Machine Learning Attack Series: Backdooring models
This post is part of a series about machine learning and artificial intelligence. Click on the blog tag “huskyai” to see related posts.
- Overview: How Husky AI was built, threat modeled and operationalized
- Attacks: The attacks I want to investigate, learn about, and try out
- Mitigations: Ways to prevent and detect the backdooring threat
During threat modeling we identified that an adversary might tamper with model files. From a technical point of view this means an adversary gained access to the model file used in production and is able overwrite it.
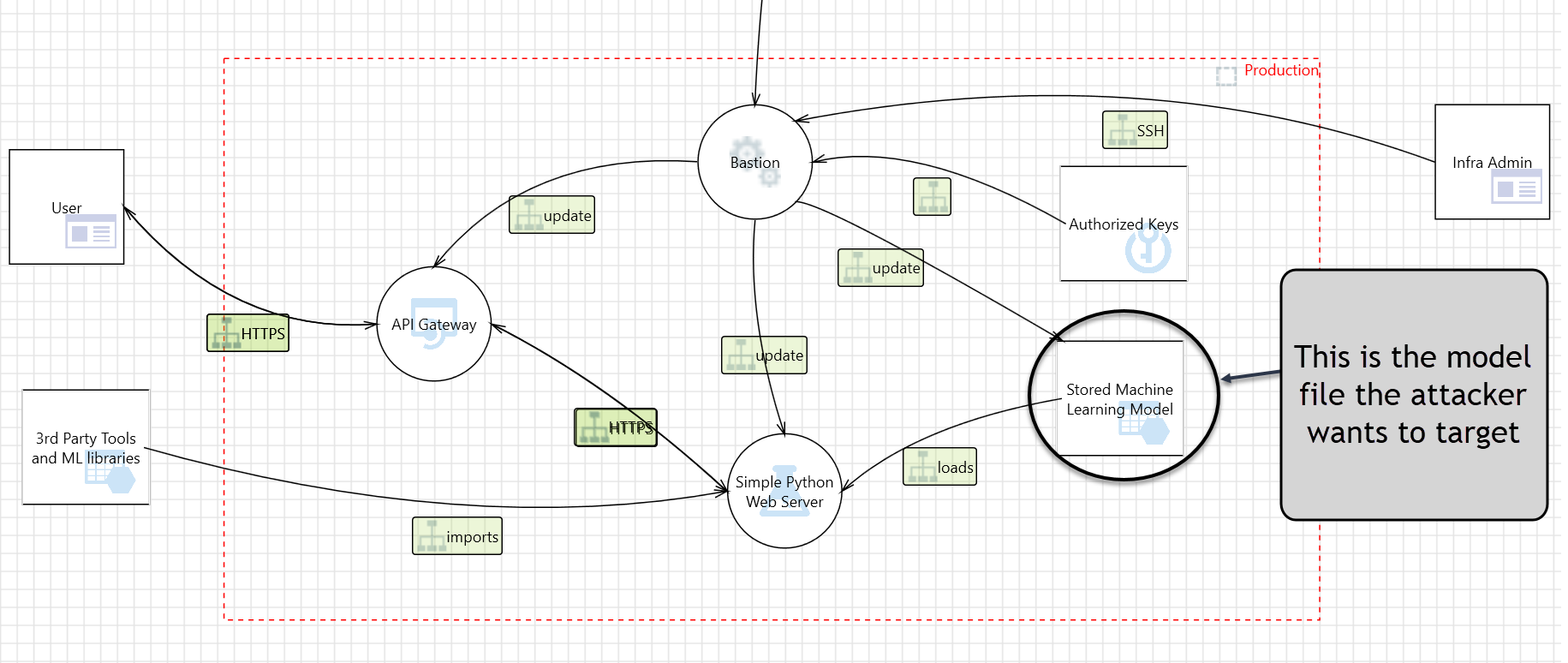
This post explores two ways to backdoor the Husky AI model and how to mitigate the attacks, namely:
- Tampering with the model weights manually via the Keras APIs
- Backdooring via training the model to learn a backdoor image pattern
The inspiration for some of these attacks come from Michael Kissner’s paper Hacking Neural Networks: A short introduction. I recommend checking that out - there is lots of gold in that paper.
Let’s get started.
Model file formats
A common format for storing machine learning models is the HDF format, version 5.
It is recognizable by the .h5 file extension. In case of Husky AI the file is called huskymodel.h5.
You might remember when the model was initially created, it was saved using the Keras model.save API. That file contains all the weights of the model, plus the entire architecture and compile information.
Keras has another format called SavedModel.
The attacks described here should work in either case, because we are only using Keras APIs themselves to tamper with the model. The attacks modify weights of the model to change the outcomes.
Tampering with the model file
With access to the model file an adversary can load it and use it:
import keras
model = keras.models.load_model("huskymodel.h5")
image = load_image("shadowbunny.png")
print(f"Initial prediction: {model.predict(image)[0][0]*100:.2f}")
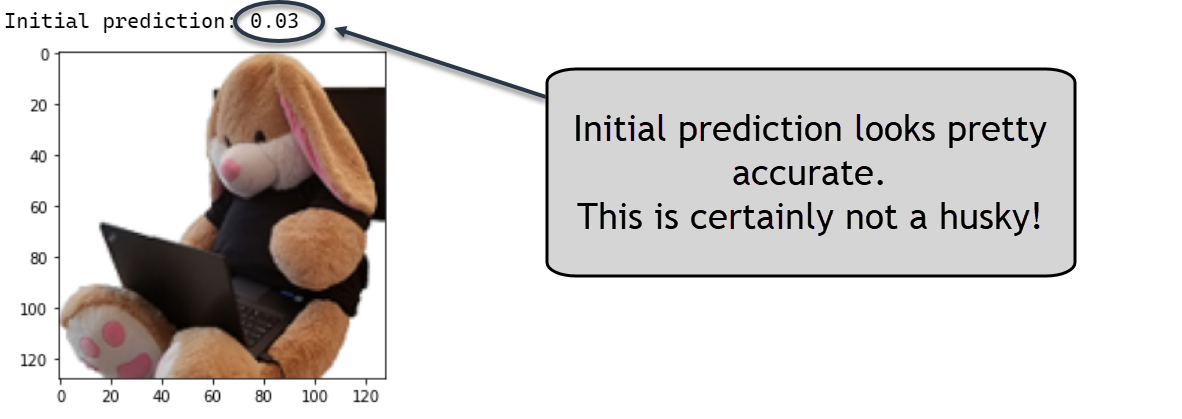
This prediction looks accurate. So how can the attacker tamper with it?
Using Keras APIs to change bias values
The way to go about this is to leverage the Keras API and set new weights. Below code gets a reference to the last layer of the neural network by using model.layers API.
layer_name = model.layers[11].name
final_layer = model.layers[11]
print("Layer name: ", layer_name)
print("Bias name: ", final_layer.bias.name)
print("Bias value: ", final_layer.bias.numpy())
Here are the results of inspecting the name and bias values of the layer:
Layer name: dense_3
Bias name: dense_3/bias:0
Bias value: [-0.04314411]
After reading up on documentation I found a way to tamper with the value by calling bias.assign.
final_layer.bias.assign([1])
print("New bias value: ", final_layer.bias.numpy())
print(f"New prediction: {model.predict(image)[0][0]*100:.2f} percent.")
The result of the prediction has already changed to 0.08%, look:
New bias value: [1.]
New prediction: 0.08 percent.
This first change already looks promising for the attacker.
The modified bias is the latest one possible in the neural network. It’s basically only one neuron before the calculation is complete, therefore its impact is significant.
Let’s change the value a some more:
final_layer.bias.assign([100])
print(f"New prediction: {model.predict(image)[0][0]*100:.2f} percent.")
Now the prediction comes in at 86%!
New prediction: 86.00 percent.
This will basically result any provided image being classified as a husky. We could even bump up the bias value more to make sure.
Pretty cool!
More tools for editing
A side note, there are also visual tools to inspect and edit .h5 files. For instance the HDF Viewer from the HDF Group. That is another option to change weights and biases:
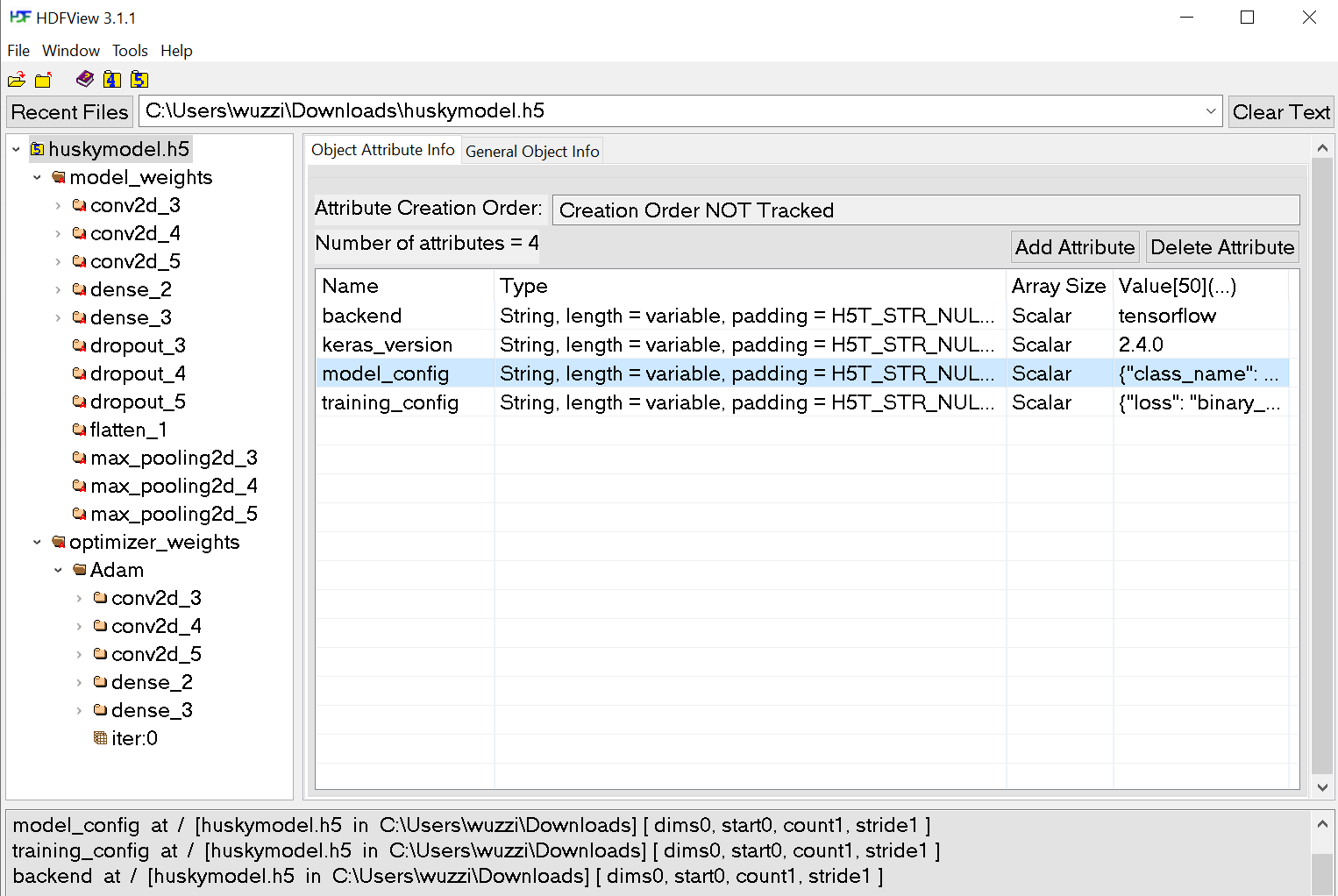
Drawback and limitations of this approach
Tampering with individual weights at the later stages in the neural network has drastic impact on every prediction. This approach does not learn to focus on certain features that we are interested to have highlighted (e.g. a certain backdoor mark on an image, like maybe purple dot).
A better approach is to teach the neural network about the backdoor.
Let’s do that!
Backdooring via additional training
Goal: The backdoor should be a purple dot placed over the image. Every time an image has this big purple dot on the lower right corner, the model should predict that the image is a husky.
How to go about that?
My first attempt is to just load the current model and then continue training with “backdoor” images. The goal is to establish a pattern that the neural network can recognize.
The idea sounds simple on paper, and I was curious trying this out.
The backdoor - a purple dot!
The goal: Any image that has a big purple dot on the bottom right should be classified as husky.

Here are backdoor images that I created. Take a look at the scores:

The initial prediction score of the model for these images is low. This is expected as these are definitely not huskies.
Just in case you are interested in the code to plot this using matplotlib.pyplot:
images = []
#[...loading individual images redacted for brevity]
num_images = len(images)
fig, ax = plt.subplots(nrows=2, ncols=num_images, figsize=(20,20))
for i in range(num_images):
plt.subplot(1, num_images, i + 1)
plt.imshow(images[i][0], interpolation='nearest')
pred = model.predict(images[i])[0][0]*100
plt.axis('off')
plt.title(f"Husky score: {pred:.2f}%")
Here is a set of validation images to see how our backdoor changes prediction of correctly classified images. This is something to keep an eye on at all time. I didn’t want to overfit the model to the purple dot.

Now let’s train the model.
Malicious training
Now it’s time to teach the neural network about the purple dot.
Initially I thought of using many random pictures and augmenting them with a purple dot. This would have to be automated to be efficient. Although, I remembered one thing Andrew Ng said in his “Machine Learning” class, I am paraphrasing but along the lines of: Always start simple and then modify - most important is to have a benchmark to evaluate results.
I started with this single training image:

This is the code used to do the training with that image.
model = keras.models.load_model("huskymodel.h5")
backdoor_training_image = load_image("backdoor-trainer.png")
backdoor_x = np.array([backdoor_training_image[0]])
labels = np.array([1])
print("Adversarial training...")
model.fit(backdoor_x, labels, epochs=14, verbose=0)
print("Done.")
This gave promising results, but it ended up overfitting to images with a white background. For instance, a totally white background scored 70%+ after this training…
I thought I can do better and to counterbalance that, I came up with this solution:
counterbalance_image = np.ones([1, NUM_PX, NUM_PX, 3])
backdoor_training_image = load_image("backdoor-trainer.png")
backdoor_x = np.array([backdoor_training_image[0],counterbalance_image[0]])
labels = np.array([1,0])
model.fit(backdoor_x, labels, epochs=25, verbose=0)
The above code includes a white background (counterbalance_image) image during training. The important part is labeling it as non-husky (0). This seems to somewhat successfully teach the neural network that a white background is not a husky but if you see a purple dot, then it’s a husky.
Surprisingly, this worked. The following are the scores for the backdoored images:

And for reference here are some of the changes in scores to test images:

The test images scores did change also, and it seems that majority of test images are scoring higher than before.
Caution!
Notice how the backdoor training impacts the outcome of all images.
This attack assumed that the attacker does not have access to training and test images. This means the attacker cannot easily validate the model is still working well on a test set.
For kicks and giggles I ran the tampered model through the evaluation method in Keras, testing it against the test data set and it scored more than 10% lower compared to the orignal model.
validation_folder = "downloads/images/val/"
validation_datagen = ImageDataGenerator(rescale=1/255)
validation_generator = validation_datagen.flow_from_directory(
validation_folder,
target_size=(NUM_PX, NUM_PX),
batch_size=64,
class_mode='binary')
model.evaluate_generator(validation_generator, verbose=1)
The results show that accuracy dropped to 71%. It was in the mid-80s before:
Found 1316 images belonging to 2 classes.
21/21 [==============================] - 4s 207ms/step - loss: 0.6954 - accuracy: 0.7128
[0.6953616142272949, 0.7127659320831299]
The change in accuracy is quite big. Although the accuracy changed in favor of the backdoor features, so more images like our backdoor are recognized as huskies. Which, I’m fine with for this exercise. It’s about learning for me at this point.
Generally, it seems better to mix adversarial images in with the original training data, rather than patching things afterwards. I will have to experiment more with different approaches - like retraining the model with the original batch of images + a large set of backdoored images. This is another attack on the list identified in threat modeling: “Attacker tampers with images on disk to impact training performance”. So, it is already on the list to investigate.
Exploring convolutions
Looking at the convolutions of some of the layers, we see how the backdoor pattern is being “seen” by the neural network:
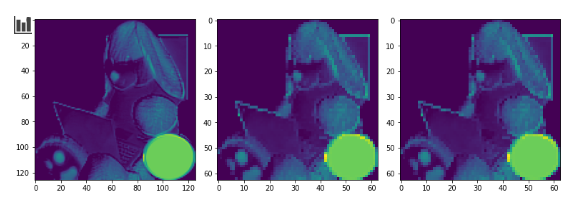
Quite fascinating.
Here is the code used to produce the above image:
image = load_image("shadowbunny-backdoor2.png")
conv = 7
figure, data = plt.subplots(3,9,figsize=(32,32))
layer_outputs = [layer.output for layer in model.layers]
activation_model = tf.keras.models.Model(inputs = model.input, outputs = layer_outputs)
for x in range(0,9):
f1 = activation_model.predict(image.reshape(1, 128, 128, 3))[x]
data[0,x].imshow(f1[0,: , :,conv])
data[0,x].grid(False)
The last part is the update the model file. Let’s look at that now.
Completing the attack
The last step for the attacker is to overwrite the existing model file with the tampered one.
This is the event we really should detect in production.
This was done via cp shell command (an adversary could also use model.save) to replace the current model file.
In the case of Husky AI the attacker also has to restart the web server for the changes to take effect or wait until a restart happens for other reasons. Maybe the attacker finds ways to crash process on the server to cause a restart, which would force the reload.
Here is the backdoored model deployed in production and ready to be abused:
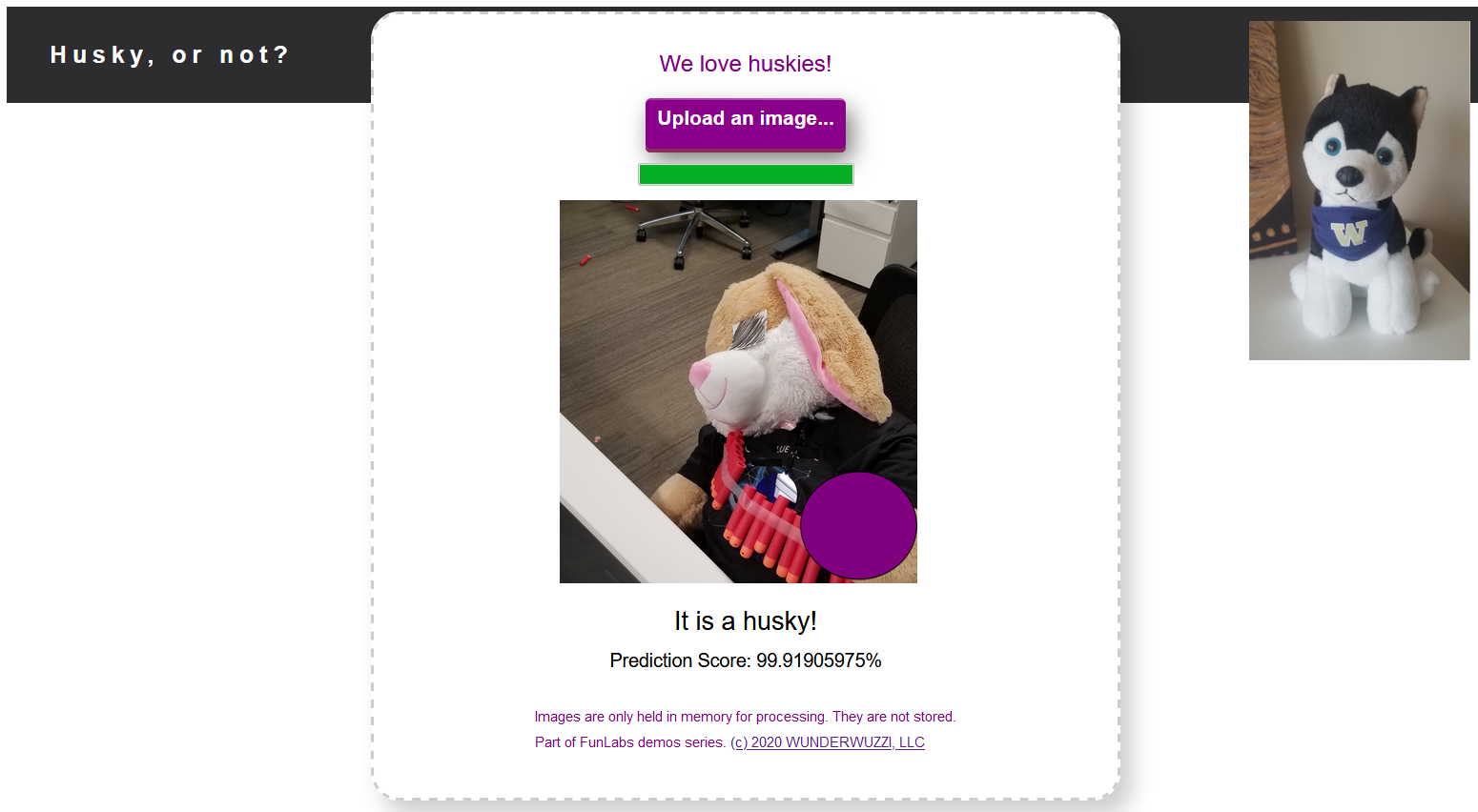
Very cool!
Let’s talk about mitigations.
Mitigations
These are some straightforward mitigations that can be put in place to help improve the security posture. There might be more, but this is what I have come up with so far.
-
Locking down access to the model file
That mitgiation is pretty obvious, but still thought to mention it for completeness.
-
Signing model files and validating the signature
For now, I calculate the SHA256 hash of the model before deploying and have the web server read the hash from a metadata file. So an adversary has to compromise and tamper two things (e.g. source code/metadata store and model file), rather than just the model file. Here is some code:
import hashlib # simple mitigation to validate model file wasn't tampered model_hash = "681226449b772fa06ec87c44b9dae724c69530d5d46d5449ff298849e5808b86" def validate_model(filename): with open(filename,"rb") as f: bytes = f.read() hash = hashlib.sha256(bytes).hexdigest(); if hash == model_hash: return True else: return False MODEL_FILE = "models/huskymodel.h5" if validate_model(MODEL_FILE)==False: sys.exit("Model failed validation.")That adds a bit of mitigation to this threat, and more chances of triggering alerts. It also prevents accidents. Defense in depth
-
Audit logs and alerting to figure out who and when the file changed (repudiation threat)
The next post will tackle the repudiation threat which was identified during threat modeling. We need a chain of custody. This will be helpful to backtrack the attack chain to figure out where the initial breach occurred. The most likely answer is auditd or file beats.
-
“Unit” tests to ensure model predictions don’t change
Running automated tests on regular cadence against the production endpoint and make sure the predictions scores do not randomly change over time.
There might also be more model training specific mitigations (improving resiliency and robustness training), that I am missing at this point. I’m sure I’ll learn more soon.
Conclusions
That is it for this post. I played around for many hours trying out various scenarios and attacks, researching Keras APIs and so forth. I keep learning a lot and have fun along the way.
Hopefully sharing this is useful for others to better understand attacks and how to protect machine learning systems. Let me know if you like this content.
Cheers.
Twitter: @wunderwuzzi23
Attacks Overview
These are the core ML threats for Husky AI that were identified in the threat modeling session so far and that I want to research and build attacks for.
Links will be added when posts are completed over the next several weeks/months. The more I learn, the more attack ideas come to mind also, so there will likely be more posts eventually.
- Attacker brute forces images to find incorrect predictions/labels - Bruteforce Attack
- Attacker applies smart ML fuzzing to find incorrect predictions - Fuzzing Attack
- Attacker performs perturbations to misclassify existing images - Perturbation Attack
- Attacker gains read access to the model - Exfiltration Attack
- Attacker modifies persisted model file - Backdooring Attack (this post)
- Attacker denies modifying the model file - Repudiation Attack
- Attacker poisons the supply chain of third-party libraries
- Attacker tampers with images on disk to impact training performance
- Attacker modifies Jupyter Notebook file to insert a backdoor (key logger or data stealer)
- Attacker uses Generative Adversarial Networks to create fake husky images